
扒光AI数字人的底裤
AI数字人,现在已经不是一个新概念,隔壁宋大爷都会拿自己年轻时候的照片,APP一顿扒拉整成会说话的帅小伙,发视频号啥的老讨大妈们喜欢了。
会用不代表懂基本原理,该被收割还是得认,尤其是传统企业的老板们,韭菜根都快被薅没了,还伸着脑袋往前送。
这不,马友会的烧烤哥近期准备搞个数字人,一看报价60个W,摸摸口袋想起了经常白嫖的老马,递了根28年的华子,让讲讲啥是AI数字人。
本着受人恩惠,砸他人饭碗不留情的做人原则,老马将从科普的角度,尽可能大白话给大家聊清楚市面上AI数字人的普遍情况,不代表一棍子打死,但至少大部分人是这么忽悠你的。
一、基本概念
先来了解一下基本的几个概念,分别是AI算法、AI模型、人体建模、声音克隆、文字生成语音、语音同步嘴型。
AI算法:多种数学模型和计算方法的应用,你可以简单的理解成为一些数学公式的计算就行了,再深入什么卷积神经网络之类的可以不用管。
AI模型:利用AI算法对数据进行分析、处理、预测和优化的数学模型,你可以简单地理解为AI模型就是AI算法的结果。
它们之间简单的逻辑关系是:AI算法 → 数据训练 → AI模型。
总结一句话,AI算法是为了解决某个问题某种任务的计算步骤和逻辑,通过大量的数据训练之后就得到了具体的AI模型。
人体建模:AI数字人既然是人,那就涉及到人体建模。这里的建模,跟AI的模型不是同一个概念,要搞清楚,人体建模主要是三维和二维,三维(3D)就是立体,二维(2D)就是平面。
目前在短视频制作上都是二维平面的人体,三维人体应用得比较少,三维人体看起来比较假,部分B站的VTuber(虚拟主播)会用到卡通的三维人体。
专业的人体建模涉及到数据采集、特征提取、模型构建、姿态估计等操作,目前短视频中的绝大部分数字人都不是人体建模,而是一个拍摄的视频。
是的,你没听错,这些所谓的数字人模型,就是让一个真人站在绿幕前,简单地摆摆手,摇摇头,动动嘴巴,做一些固定的动作,拍成一个视频。
这样的视频因为是用绿幕拍摄的,所以视频抠像(类似于绿幕抠图)换别的背景是很容易的事情。

图片来自网络
声音克隆:比如你的高德地图语音包用的是林志玲姐姐,林姐姐的声音就是克隆的。现在只要你愿意动手,先录制一些自己的声音素材,使用诸如GPT-SoVITS、Bert-VITS2等开源项目,就可以复制你的声音。
声音克隆的逻辑关系是这样的:声音数据 → 克隆算法 → 训练模型 → 模型推理(文本生成语音)。
文字生成语音:克隆完你的声音之后,有了自己的声音模型,你就可以输入文字,让模型帮你生成一段语音,专业名词叫TTS,最后这段语音就好像你自己讲出来的一样。
语音同步嘴型:跟自己声音一样的语音有了,那么就可以用语音来匹配视频中人物讲话的嘴型,使得嘴型跟所讲的内容对应,俗称对嘴型,看起来更加真实,更像真人。
同样的,如果你动手能力强,使用开源项目Wav2Lip,让一张照片、一段视频讲话,嘴型对得上,声音也是自己的,完全没问题。
了解以上这些概念,AI数字人具体是怎样实现的,就很容易理解了。无非几种方式叠加应用而已,下面具体说说市面上常见的AI数字人类型,及其实现的方式。以下数字人1.0-3.0是老马个人的分类方式,与行业标准无关。
二、数字人1.0
先说结论,不存在真正的人体建模,拍了一堆不同人物的视频,假装成数字人模型,有男女老少,不同身份,不同国籍,不同服装等等让你选择,如图:

图片来自网络
没有声音克隆,只有一些现成的说话人给你选择,比如讲东北话的张三,讲河南话的李四,萝莉音的小美等,你输入文字选择完说话人就能生成一段语音,语音再加上现成拍好的人物视频,一合成就成了所谓的AI生成的数字人视频。
数字人1.0你要真非得跟AI扯上点关系,也就是里面的“文字生成语音”算是AI,其它就跟你自拍个视频,放到剪映里面,把声音禁用掉,再自己录一段别的语音,拖进去剪映,加点字幕,不就变成一段新的视频了么,道理是一样的。
所以你看到很多所谓的数字人,嘴型跟讲的内容根本对不上,或者相差很大,很别扭,头部脸部手部动作都一样,基本都属于上面的操作,就这样都好意思叫数字人。
三、数字人2.0
没有人体建模,你可以提供自己出镜拍摄的视频,不再局限于现成的那些固定人物视频,然后进行数字人克隆。
克隆你本人,是需要人体建模的,所以这里所谓的数字人克隆,还是用你出镜拍摄的视频,假装成数字人模型,跟数字人1.0一样。
有声音克隆,你需要录制一些自己的声音素材提交给平台软件,去克隆生成自己的声音,原理上面讲过。
有文字生成语音,不再局限于哪些现成的说话人,你可以自行输入文字,再利用前面的声音克隆做出来的模型,生成专属于你自己的语音。
有语音同步嘴型,生成自己的语音,再去驱动视频里的自己自动说话,同步对上嘴型,这样看起来不就逼真了么,如图:

图片来自网络
数字人2.0用到AI技术有声音克隆、文字生成语音、语音同步嘴型三种,存在的问题就是,无论你制作多少个视频,你的头部脸部手部等肢体动作都是一样的,除非你再录制一个肢体动作不一样的视频去生成。
判断是不是数字人2.0,可以仔细观察鼻子到下巴的位置,会明显看到一个透明的方框,方框内的画面明显模糊,或者变形,这是由于语音同步嘴型,需要去修改视频每一帧的画面所导致的。
四、数字人3.0
坦白来说,目前老马还没有看到真正的数字人3.0,或许老马孤陋寡闻了。但是仅仅要实现人体建模,其成本也是不低的。未来的数字人,应该是要结合GPT的,这块展开篇幅就长了,也不是本文讨论的主题。
最后下个结论,类似于实现数字人1.0和数字人2.0的技术很难吗?成本很高吗?答案是否定的,除了使用开源项目自行搭建操作,完全不懂技术的小白,也可以在某宝找到傻瓜式一键生成的软件(也是基于开源项目),如图:
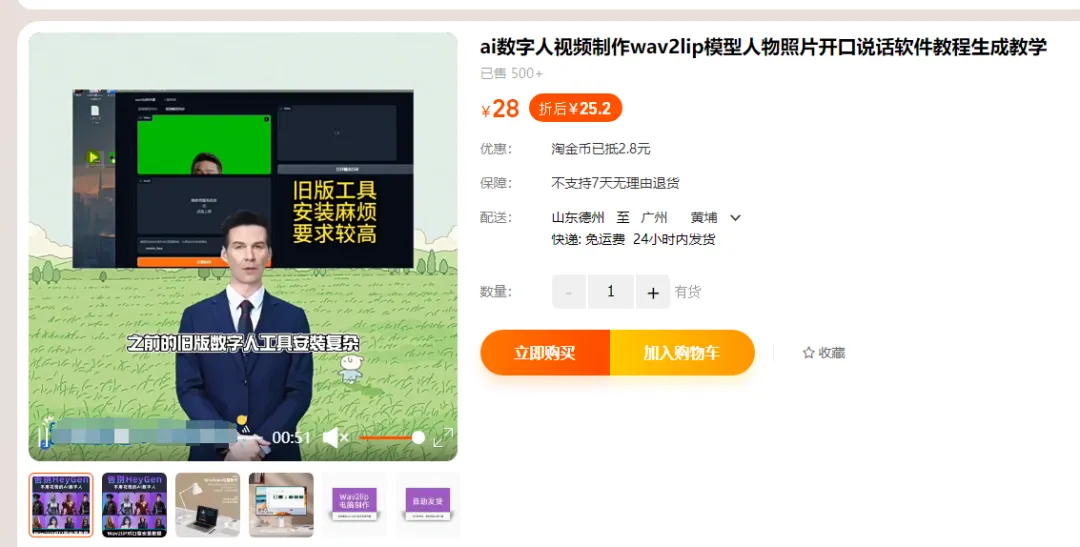
图片来自网络
大概一百块有找零,自己摸索的话差不多了,做出来的效果达到能用的水平问题不大。市面上动不动多少个w的数字人服务,老马只能说不排除有做得真正效果很牛逼的,但绝大部分都是吹牛逼的。
到此撂笔,下课!

